笔者近期上了国科大周晓飞老师《强化学习及其应用》课程,计划整理一个强化学习系列笔记。笔记中所引用的内容部分出自周老师的课程PPT。笔记中如有不到之处,敬请批评指正。
文章目录
- 2.1 动态规划:策略收敛法/策略迭代法
- 2.2 动态规划:值迭代法
总的来说,DP方法就是在已知bellman方程的环境参数(回报R和转移概率P)的情况下,求取最优策略 u ∗ u^* u∗和最优值 v ∗ v^* v∗。
2.1 动态规划:策略收敛法/策略迭代法
总体思路:算V --> 算Q --> 策略改进 (不断重复)
初始化最优策略 u,
Step1 策略评估: 确定当前策略 𝜋 的值函数
V
π
V^π
Vπ,可通过下面的式子求解。
Step2 计算动作值函数Q: 使用值函数 V π V^π Vπ来计算每个状态-动作对的动作值函数 Q π ( s , a ) Q^π(s,a) Qπ(s,a)。这一步是为了计算在当前策略 𝜋 下,每个状态-动作对的期望回报。
Step3 策略改进: 对每个状态 𝑠 选择能使
Q
π
(
s
,
a
)
Q^π(s,a)
Qπ(s,a)最大的动作𝑎,从而形成新的策略 𝜋′。这一步是为了更新策略,使其更接近最优策略。
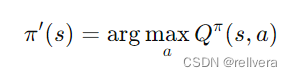
Step4: goto Step1, 直到最优策略u不变。
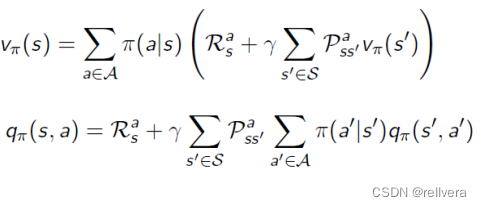
2.2 动态规划:值迭代法
值迭代(Value Iteration)是一种用于求解马尔可夫决策过程(MDP)的经典动态规划算法。它通过迭代地更新值函数,逐步逼近最优值函数
V
∗
V^*
V∗ ,最终得到最优策略
π
∗
π^*
π∗。
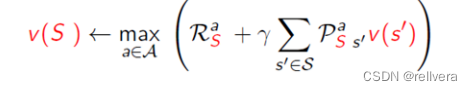
值迭代一般分为这几个步骤:
step1 初始化:设定初始值函数
V
(
s
)
V(s)
V(s)为零或其他任意值。
step2 迭代更新:对于每个状态 𝑠 ,根据当前值函数
V
k
V_k
Vk计算新的值函数
V
k
+
1
V_{k+1}
Vk+1。这个更新过程通过遍历所有状态和所有可能的动作,计算在每个状态下采取每个动作所能获得的期望累计奖励,并选择其中的最大值作为新的值函数值。
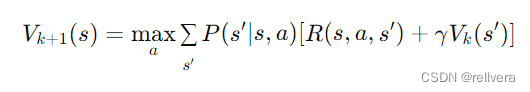
step3 收敛判定:当值函数的变化小于某个预设的阈值 𝜃 时,认为值函数已经收敛,可以停止迭代。
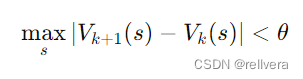
step4 策略提取:在值函数收敛后,通过值函数
V
∗
V^*
V∗ 提取最优策略
π
∗
π^*
π∗:
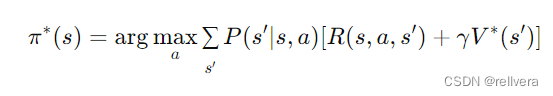
关于值迭代,也有很多处理技巧,这里简单介绍三种。
(1)In-place Dynamic Programming
在标准的值迭代过程中,我们通常会维护两个值函数,一个用于保存当前迭代的结果,另一个用于保存上一次迭代的结果。而在 In-place Dynamic Programming 中,我们只使用一个值函数数组,在每次更新时直接覆盖旧的值。
特点:只需要一个数组来存储值函数,减少了内存消耗。
(2)Prioritized Sweeping
是一种加速值迭代的方法,通过优先更新那些对值函数变化影响较大的状态,从而提高收敛速度。
(3)Real-time Dynamic Programming (RTDP)
是一种在实际运行过程中更新值函数的方法,适用于在线学习。